
How Search Engines Work? What Are the Different Stages of Google Search?
Before you start with link building and other on-page activities, it is essential to understand how search engines work and what are the different stages of Google search.
There are several processes that play a key role in bringing up your web content on search results pages. Each of these processes might have subprocesses involved within them.
Let us discuss the 4 main processes or stages of Google Search.
1. Crawling
Whenever a user searches for a term or page on the search engine, the search engine sends an immediate request to the website server for webpages using its automated programs. These programs collect information or a copy of the page and relevant links from the server. Once it has retrieved the requested webpage, it will proceed to the next link on its list of unvisited links. This whole process is referred to as crawling or spidering.
Let me make it more simple for you. Search engines have their automated programs called bots, crawlers, or spiders that visit your website to discover and download text, images, and videos from all pages found on the Internet.
In short, the main job of crawlers is to discover and collect the information available on the website.
Each search engine has its own bot, for example, “Googlebot” for Google, “Bingbot” for Microsoft, and more. For crawling mobile pages or ads or any other information, there are different bots.
This whole process of crawling might sound simple but comes with a wide range of challenges. At times, there can be several reasons your domain or specific page is not being crawled by the search engine.
So, make sure that you provide a link to the search engine bots where they can find all the pages on your website, i.e., submit a sitemap.
In case you want to stop bots from crawling specific pages, make sure to edit your robots.txt file.
2. Rendering
The second stage of Google search is to render the pages. Google sends its crawlers to the website to render each page, that is, turn all the HTML, CSS, and JavaScript codes into an interactive page, making it easier for users to understand the information. This step is necessary for the search engine to comprehend how the content of the webpage is presented in context.
You can also say that rendering is a sub-process of the crawling stage. But, this process also comes with a wide range of challenges.
Google leverages “Rendertron,” an open-source rendering engine based on the Chromium browser system, for taking snapshots of web pages to show it in their search results. On the other hand, Bingbot renders websites and runs JavaScript using Microsoft Edge as its engine.
Read More: How Can I Check What Googlebot Renders on Visiting My Website/Article?
3. Indexing
Once the web page has been crawled and rendered by the bots, it is now time to determine whether to store it in the index or not.
Google index is a large database that stores all the information, i.e., your images, text as well as video files on the website.
For example, when you visit Google and type a search query, you see a big list of results on the search results page. These are indexed results.
Let me make it more simple for you.
You search thewebstore27 on Google. Now, you see my website is ranking on Google.
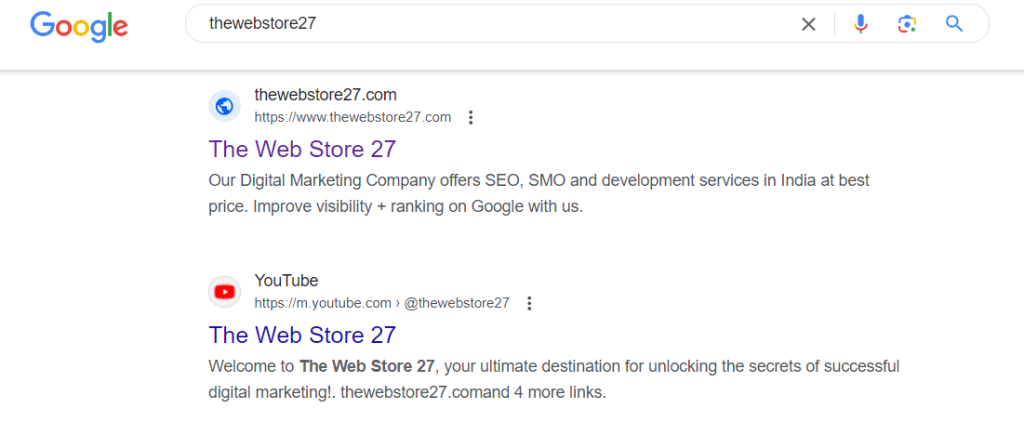
If my website was not indexed, it would show you this snapshot.
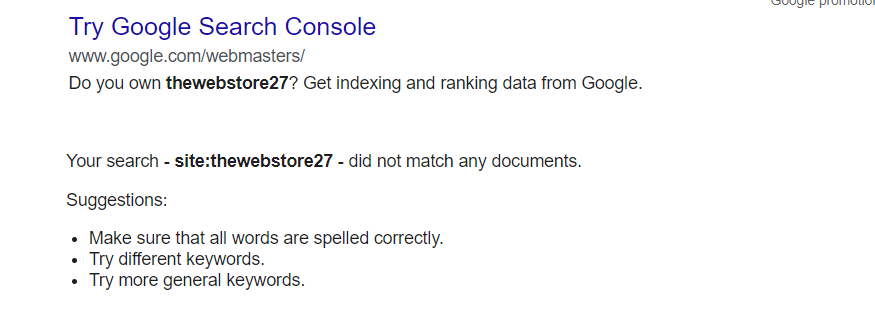
The best way to track whether your web page or website has been indexed on Google or not is to type site:your website link.
For example, site:thewebstore27.com
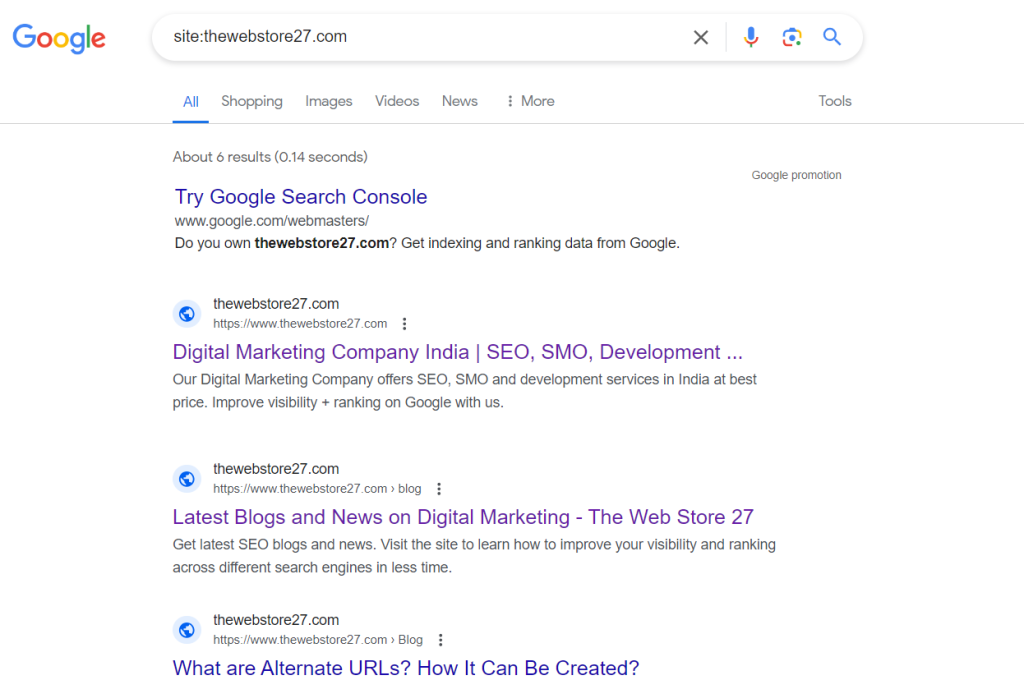
It will show you all the pages that have been indexed by Google for your website.
Similarly, to check if a particular web page or backlink created by you on third-party sites has been indexed on Google or not, try the site query.
Read More –Why All My Pages Do Not Show in Site: Query?
Note: not every page that is crawled will be retained in the search index. A page can ask a search engine not to index it, for example, if it has a robots meta tag with a “noindex” directive.
Similar to this, a webpage may have an X-Robots-Tag telling search engines not to index it in its HTTP header.
Google also says that low-quality web pages might not be stored in the index. The absence of full indexation for a website might also be caused by an inadequate crawl budget.
Hence, it is crucial to diagnose and correct when pages do not get indexed.
Even though a page is indexed, Search Console may inform you that it is not displayed in search results. This could be the case because:
- The page’s content has nothing to do with the users’ queries or is highly irrelevant
- The content quality is low
- Serving is prohibited by robot meta rules.
4. Serving Search Results or Ranking
Once a search engine gains access to all of your web pages, its next step is to decide which page to rank on Google for what keyword phrase and at which position.
If you have been working in this industry, you might already know how the ranking process works. You can also call the ranking process of Google search “algorithms”.
There are different criteria based on which your web pages rank on Google. The search engines give preference to the highest quality and most relevant information based on the user’s query.
For example, if you search for mobile repair shops, you are most likely to get a list of local stores near you that offer mobile repair services with no image results. On the other hand, if you search for the latest mobiles, you might get products listed on your screen with images but no local results.
To decide what to show and what not to, Google has a list of hundreds of factors.
In 1996, Google introduced its ranking algorithm – PageRank. The foundation of the idea was the ability to compute links to a webpage and the relative weight of the sources of those links in order to ascertain the ranking strength of that page in relation to all other pages.
These days, Google uses a kind of drip approach to determine rankings, which allows pages and updates to be taken into account much more quickly without requiring a month-long link-building process. Additionally, new page links are added on a daily basis.
Furthermore, links are evaluated using complex algorithms that can reverse or lessen the ranking power of links that have been bought, exchanged, spammed, approved by editors, and more.
Conclusion
Gaining expertise in the fundamental phases of search is essential for advancing in the SEO field.
Understanding the differences between crawling, rendering, indexing, and ranking procedures is a good idea. Having an unclear grasp of these phrases, though, wouldn’t, in my opinion, be a deal-breaker.
Experts in SEO have a range of backgrounds and degrees of expertise. It matters that they are capable of learning and developing a basic degree of comprehension.
How to Set Up Google Analytics?
For latest updates on SEO and GEO practices, follow on LinkedIn.